

#Llama2-Chat
Llama2's finely tuned variant, Llama2-Chat is optimized for dialogue use cases. To ensure safety and helpfulness, Llama2-Chat employs Reinforcement Learning from Human Feedback (RLHF) with over 1 million human annotations, which involves learning from human interactions to improve the model's responses. In this tutorial, you'll discover the process of locally running the 7B variation, Llama2-7B-Chat, using Instill Core.
#Prerequisites
To launch Instill Core, please make sure that you have installed the following tools:
- macOS or Linux - Instill Core works on macOS or Linux, but does not support Windows yet.
- Docker and Docker Compose - Instill Core uses Docker Compose (specifically,
Compose V2and Compose specification) to run all services locally. Please install the latest stable Docker and Docker Compose. yq>v4.x. Please follow the installation guide.
Note that running the Llama2-7B-Chat model locally necessitates GPU support. To run Llama2-7B-Chat locally, you will need a Nvidia GPU with at least 16GB of VRAM. If you don't have access to a GPU, please proceed to the Run Llama2-7B-Chat on Instill Cloud section.
#Launch Llama2-7B-Chat locally
#Step 1: Launch Instill Core
Open your terminal and run the following commands to set up Instill Core with Docker Compose:
$ git clone -b v0.29.0-beta https://github.com/instill-ai/instill-core.git && cd instill-core$ make all
Once all the services are up, the no-code Console is available at http://localhost:3000. Log in with username admin and the default password password (you can change this later).
#Step 2: Create the model via no-code or low-code methods
There are two main ways to create the Llama2-7B-Chat model in Instill Core: no-code and low-code. No-code offers a user-friendly interface, while low-code provides more control through API calls.
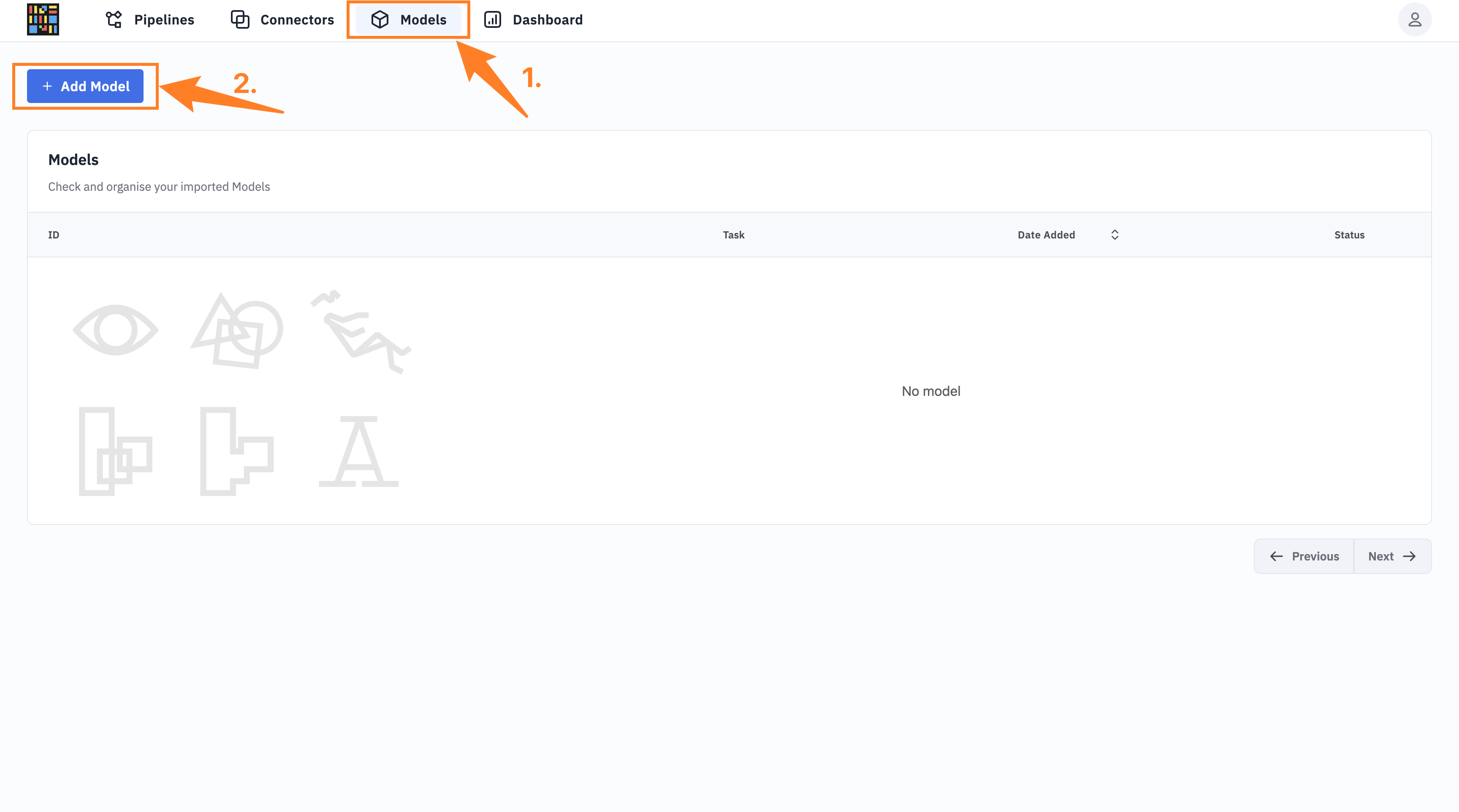
#Create the model via no-code
After onboarding, you can navigate to the Models page and click + Add Model and enter the model details as found on the GitHub repository.
Alternatively, you can create the model via API.
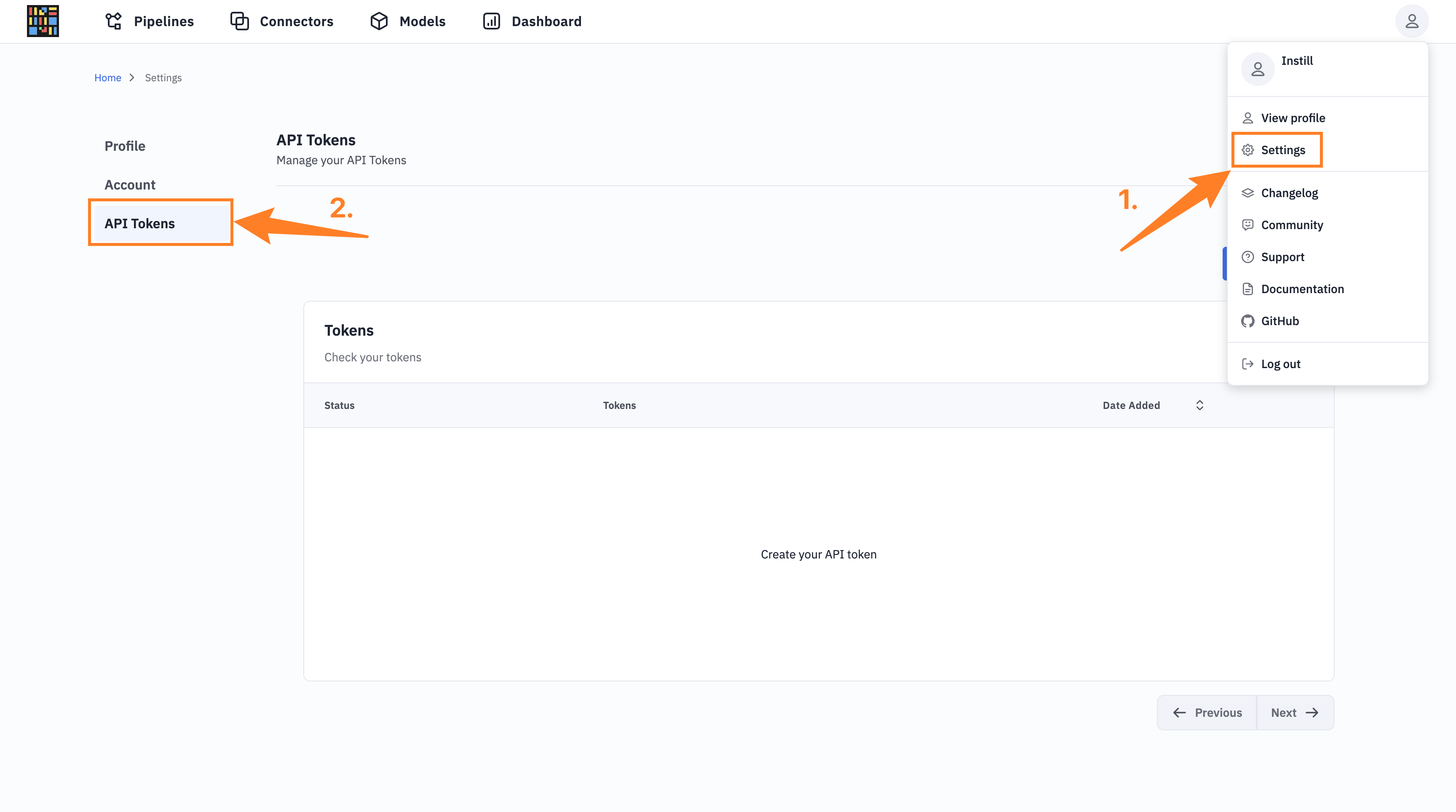
Obtain an Instill Core API Token
Go to the Settings > API Tokens section, then click on Create Token. Be sure to copy the token for future use.
#Create the model via low-code
Run the following command to create and deploy the model
curl --location 'http://localhost:8080/model/v1alpha/users/admin/models' \ --header 'Authorization: Bearer YOUR_INSTILL_CORE_API_TOKEN' \ --header 'content-type: application/json' \ --data '{ "id": "llama2-7b-chat", "description": "Deploy the LLama 2 Chat model via Instill Core", "model_definition": "model-definitions/github", "configuration": { "repository": "instill-ai/model-llama2-7b-chat-dvc", "tag": "f16-gpuAuto-transformer-ray-v0.8.0" }}'
#Deploy the model via low-code
curl --location -X POST 'http://localhost:8080/model/v1alpha/users/admin/models/llama2-7b-chat/deploy' \ --header 'Authorization: Bearer YOUR_INSTILL_CORE_API_TOKEN'
#Step 3: Run the model for inference
It may take some time to pull and deploy the model. Navigate to the Models > llama2-7b-chat page. Once the model's status is online, you're all set to run it for inference.
curl --location 'http://localhost:8080/model/v1alpha/users/admin/models/llama2-7b-chat/trigger' \\--header 'Content-Type: application/json' \\--header 'Authorization: Bearer YOUR_INSTILL_CORE_API_TOKEN' \\--data '{ "task_inputs": [ { "text_generation_chat": { "prompt": "I do not feel good today" } } ]}'
You will get a response similar to this:
{ "task": "TASK_TEXT_GENERATION_CHAT", "task_outputs": [ { "text_generation_chat": { "text": "Oh no, I'm so sorry to hear that you're not feeling well today! 😔 Can you tell me more about how you're feeling? Sometimes talking about it can help. Is there anything in particular that's bothering you, or is it just a general feeling of not being well?" } } ]}
Alternatively, you can run the model through Instill Cloud.
#Run Llama2-7B-Chat on Instill Cloud
The Llama2-7B-Chat model is available on Instill Cloud. Simply register an Instill Cloud account to gain easy access not only to this model but also to other state-of-the-art LLMs.
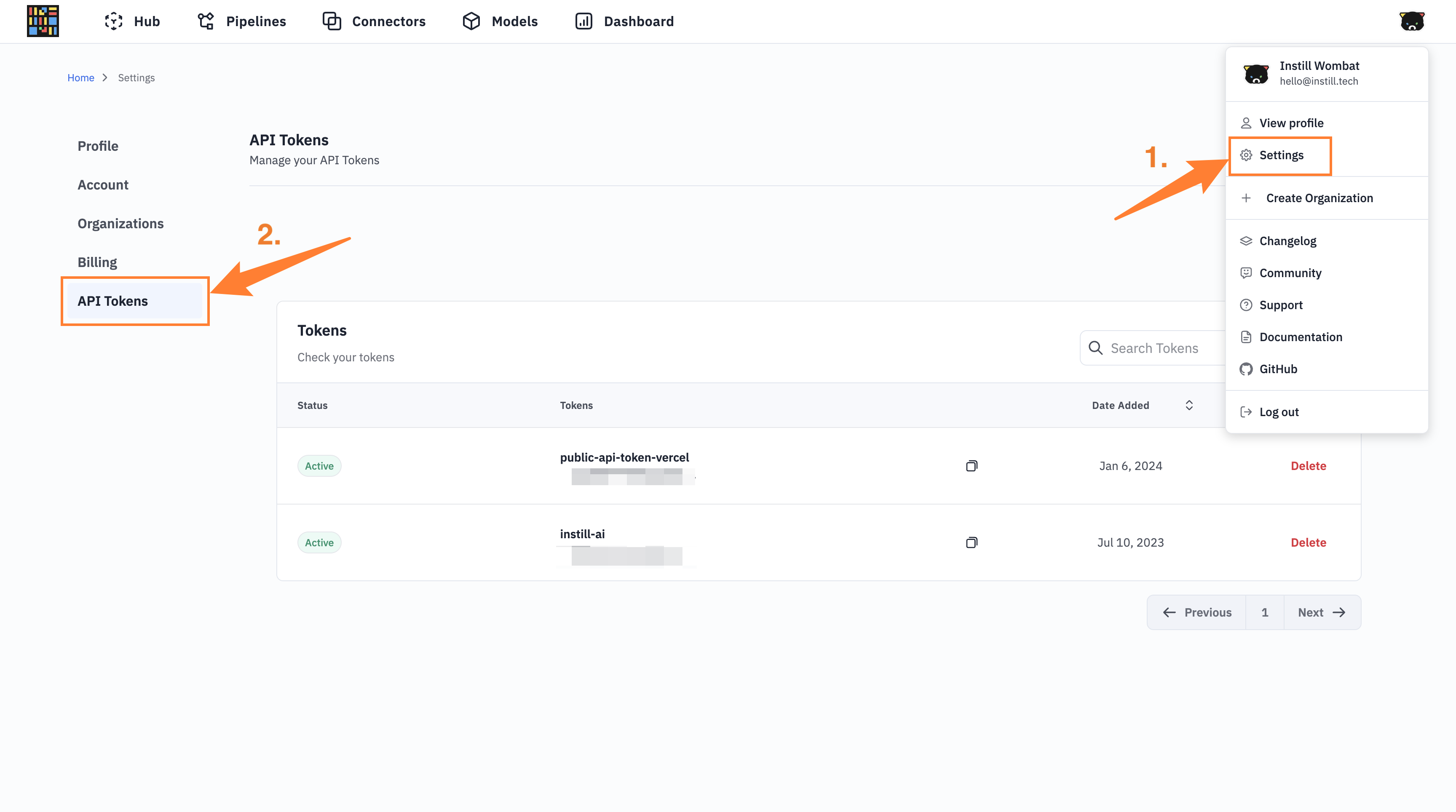
#Step 1: Obtain an Instill Cloud API Token
- Sign in to Instill Cloud and navigate to the Settings > API Tokens section.
- Click on Create Token and copy the token for later use.
#Step 2: Run the model on Instill Cloud
Replace YOUR_INSTILL_CLOUD_API_TOKEN with the API token you got from the previous step and run the following command:
curl --location 'https://api.instill.tech/model/v1alpha/organizations/instill-ai/models/llama2-7b-chat/trigger' \ --header 'Authorization: Bearer YOUR_INSTILL_CLOUD_API_TOKEN' \ --header 'content-type: application/json' \ --data '{ "task_inputs": [ { "text_generation_chat": { "prompt": "I do not feel good today", "max_new_tokens": 1024 } } ]}'
max_new_tokens: 1024 specifies the maximum number of tokens the model should generate in the response.
#Use the model in Versatile Data Pipeline (VDP)
Models deployed on Instill Core can be seamlessly integrated into a VDP pipeline for practical use. Take a look at this pre-built pipeline featuring the Llama2-7B-Chat model.
The web demo card you see below is powered by the VDP pipeline we mentioned earlier. This pipeline processes user input and sends it to the Llama2-7B-Chat model for chat interaction. In essence, VDP pipelines serve as the backbone of any AI application, enabling you to construct your own AI applications leveraging these pipelines.
AI compananion
Start a conversation with AI model
Oh no, sorry to hear that you're not feeling good today! 😔 Can you tell me more about how you're feeling? Sometimes talking about it can help. 🤗 Is there anything in particular that's bothering you, or do you just feel generally unwell?
You can start chatting with the model with the following prompt:
Prompt = I don't feel good today
Llama2-7B-Chat OUTPUT
Oh no, I'm so sorry to hear that you're not feeling well today! 😔 Can you tell me more about how you're feeling? Sometimes talking about it can help. Is there anything in particular that's bothering you, or is it just a general feeling of not being well?
#Conclusion
With Instill Core, you can deploy LLMs and experience their magic directly on your local machine. And if self-hosting isn't feasible for you, forget about infrastructure worries. Easily access LLMs on Instill Cloud without dealing with weird dependencies, enormous model weights, GPUs, CUDA, and more.
